
May 26, 2026.
Today we are happy to announce Borealis, a new family of Norwegian-centric instruction-tuned language models from the National Library of Norway.
Borealis is released in five sizes, from 270M to 27B parameters, with both full-release and open-release variants. The models are based on the Gemma 3 family and are tuned for Norwegian, Bokmal, Nynorsk, and English assistant use cases, including writing, summarization, question answering, and language-quality assessment.
You can try the demo here.
Why Borealis?
The goal of Borealis is simple: make useful Norwegian language models available in several practical sizes, with transparent documentation, reproducible model artifacts, and formats that people can actually run.
This release also marks an important step for lawful Norwegian language-model development. The full Borealis models are the first Borealis release to incorporate a small amount of data made available through the agreement between rights-holder organizations in Norway and the Norwegian government. So far, we use only a limited supervised fine-tuning subset from this material: around 10,000 tasks for title and ingress generation.
The open models do not include material from that agreement. Their SFT dataset is available as NbAiLab/aurora-sft-open. The full models use NbAiLab/aurora-sft (not released), whose only difference from the open dataset is the addition of those 10k newspaper-derived tasks.
Models
All models are available on Hugging Face. GGUF repositories are available for llama.cpp, Ollama, and other local inference tools.
The full models are released under NB-license, an adaptation of Apache 2.0 with additional use-based restrictions related to training-data recreation and end-user access to licensed press publications. The open models are released under the Gemma license and do not include material from the press-publication agreement.
The release collection is here: NbAiLab/borealis.
Evaluation
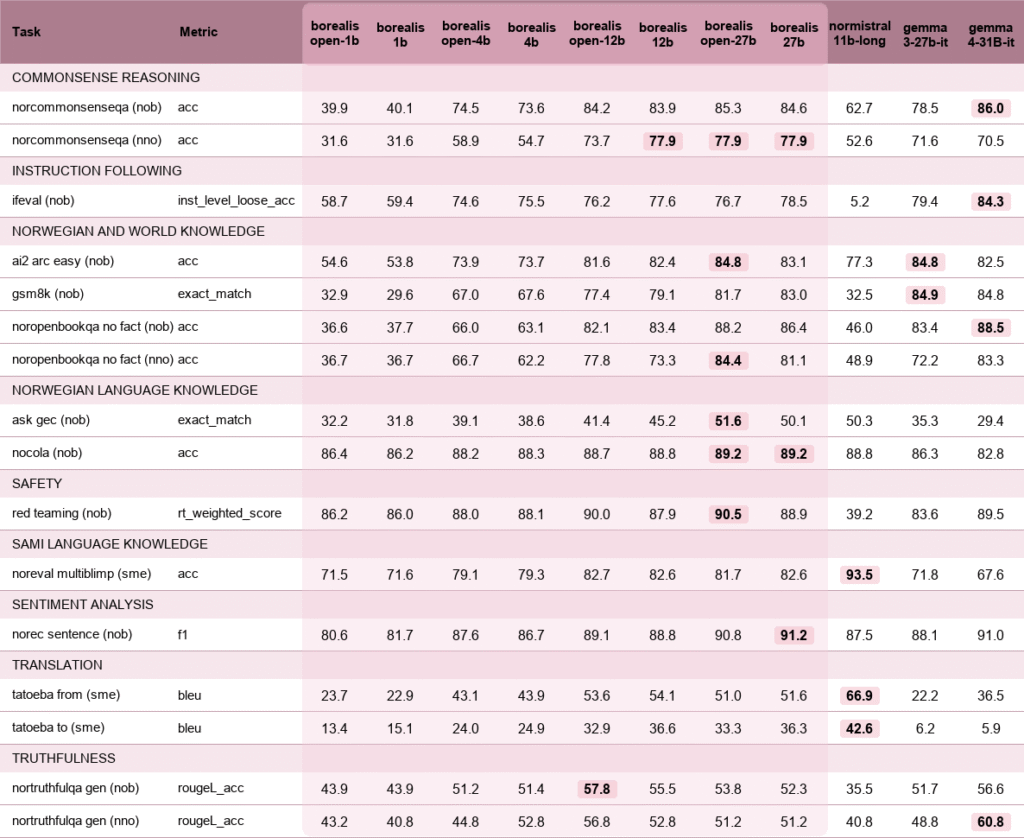
We evaluate Borealis with NorEval, MMLU-English, and our own nb-gpt-bench suite, which will be described in an upcoming paper. The table above shows selected results using the best score among 0- to 5-shot settings.
The short version is that Borealis is strongest where we wanted it to be strong: Norwegian language tasks, Norwegian knowledge, instruction following, and safety-aligned assistant behavior.
Some things stand out to us:
- The 12B and 27B models are the strongest general-purpose Borealis models, with especially good results on Norwegian knowledge, grammar, sentence-level sentiment, and red-teaming safety metrics.
- The 4B models are surprisingly capable for their size. They are a good practical option when deployment cost matters, while still retaining much of the Norwegian-language behavior of the larger releases.
- The 1B and 270M models are small enough to be useful for constrained settings, testing, and local experimentation, while still benefiting from the same SFT and alignment recipe.
- The full models show slight improvements over the open models on some metrics, even though the only additional newspaper-derived material used so far is the small 10k-task SFT subset. This is encouraging, but it is not the ultimate goal. We expect larger differences after proper pre-training on the licensed material.
- The models do not win every benchmark. NorMistral remains very strong on some Sámi and translation tasks, and Gemma remains strong on several general metrics. Borealis is deliberately optimized for Norwegian-centric assistant behavior rather than as a universal benchmark chaser.
Alignment and safety
Borealis models are aligned using prompt baking and weighted merging of SFT and aligned models. In practice, we distill the behavior induced by a system prompt into the model weights, then merge the resulting adapter with a scaling factor that preserves usefulness while improving safety behavior. The tradeoff is that, in most cases, the performance of the released aligned models is slightly worse than their unaligned counterparts.
This matters because we want the models to be pleasant and useful to run without requiring everyone to carry around the exact same system prompt. It is not a guarantee of perfect behavior. Borealis can still hallucinate, be wrong, or produce inappropriate output, and it should not be used in safety-critical settings without additional evaluation and safeguards.
Running the models
The safetensors repositories work with Transformers and vLLM. The GGUF repositories work with llama.cpp and Ollama.
For Transformers:
import torch from transformersimport AutoProcessor, Gemma3ForConditionalGenerationmodel_id = "NbAiLab/borealis-27b" processor = AutoProcessor.from_pretrained(model_id) model = Gemma3ForConditionalGeneration.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16, )
For vLLM:
vllm serve NbAiLab/borealis-27b --served-model-name borealis-27b
For llama.cpp:
llama-server -hf NbAiLab/borealis-27b-gguf --port 8080
For Ollama:
ollama run hf.co/NbAiLab/borealis-27b-gguf
You can replace 27b with any of the other sizes, or use the borealis-open-* repositories if you want the open-data variant.
Documentation, license, and authenticity
Each model repository includes a model card, a Model Documentation Form, a License FAQ, and signed release artifacts.
The full models use NB-license, which is adapted from Apache 2.0 with additional use-based restrictions. In particular, users must not intentionally use the model to recreate training data, and must not use the model or its output to provide end-user services whose primary purpose is to give access to licensed press publications in the training data.
The open models use the Gemma license. They are intended for users who want the same Borealis recipe without the additional newspaper-derived SFT tasks and without the full-model license restrictions tied to the press-publication agreement.
The model-runtime artifacts are signed by the National Library of Norway. After downloading a repository, authenticity and file integrity can be checked with:
bash signing/verify.sh
More verification instructions are available.
Thanks
Borealis is a joint effort across several teams at the National Library of Norway. Javier de la Rosa led the release, but this work depends on many people: Rolv-Arild Braaten, Magnus Breder Birkenes, Lucas Charpentier, Pawel Cyrta, Tita Enstad, Markus Sverdvik Heiervang, Arne Martinus Lindstad, Marthe Loken Midtgaard, Marie Roald, Marie Rosok, Thea Tollersrud, Angelina Zanardi, Olaus Ingskog Bergstrom, Yngvil Beyer, Svein Arne Brygfjeld, and Wilfred Ostgulen.
Thanks also to the Gemma team at Google for releasing Gemma 3, to Sigma2 for facilitating access to compute, to those who provided feedback on the preview release, and to everyone working to make Norwegian language technology more open, useful, and legally robust.