SPIFF utilizes an Elasticsearch base to index all text extracted from the images. The whole image collection is preprocessed to a specially constructed OCR engine to extract all the text content. The system is synchronized with all the images within our digital library. Here is an example of how the system present itself:
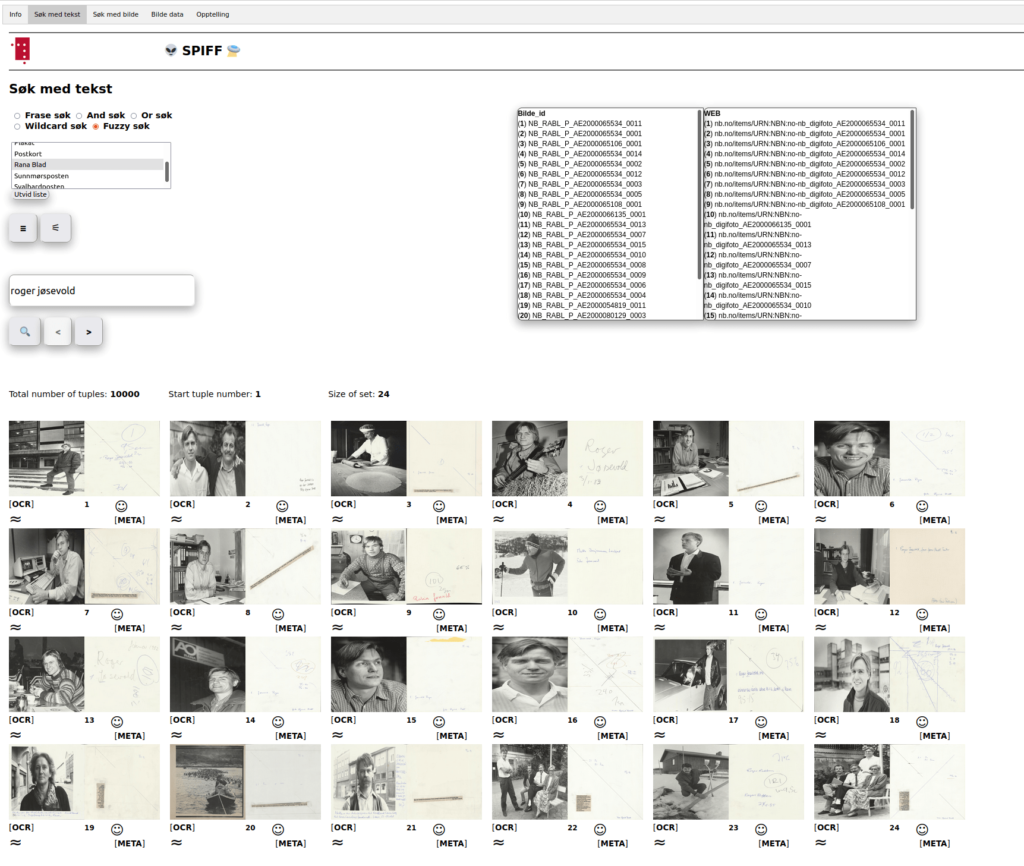
Current search is a search for “Roger Jøsevold” in the collection Rana blad. Since we know that there could be errors in the OCR interpretation of handwriting, I have used fuzzy search to allow for for spelling errors. That also gives us more hits then we expect. But this is a good thing for the user since the librarian may just small fragments of (sometimes misspelled) text to search for