Background
The Sami Bibliography holds metadata for publications relevant to the Sami community in Norway, and it is maintained by a special office at the National Library of Norway (NLN). Until now, the workflow involved the physical transportation of (eventually all) publications in Norway to and from this office. Both the transport in itself and the physical handling and reading of the items is laboursome, and those operations do not by themselves contribute to the bibliography.
Most of the items handled by the office also exist as digital versions within the collection at the library. Only a very small fraction of the total number of publications are relevant for the Sami Bibliography.
Goal
The NLN decided to run an experiment to investigate whether this workflow could benefit from the support of an AI-based system. Based on a model trained on content and metadata both from and outside the existing Sami Bibliography, it should be possible to assist the workflow in the office by suggesting candidates for the Sami Bibliography based on analyzing the content of the digital versions of the items. This process could be carried out both on historical digitized volumes as well as new publications, delivered to the library within the legal deposit agreements. However, the definition of what makes a publication relevant is not very strictly defined and it is usually up to the expert opinion of the bibliographers to determine upon the close examination of the items.
Modeling relevancy
Dataset
In order to be able to produce a model capable of predicting whether a record in the NLN catalog could potentially be of relevance for the Sami Bibliography, we first had to collect a curated dataset with samples of entries already in the bibliography (the positive class), and samples not contained and ideally not relevant for the Sami Bibliography (the negative class). We then built a binary classifier that given any text would assign a probability for it being relevant for inclusion in the Sami Bibliography.
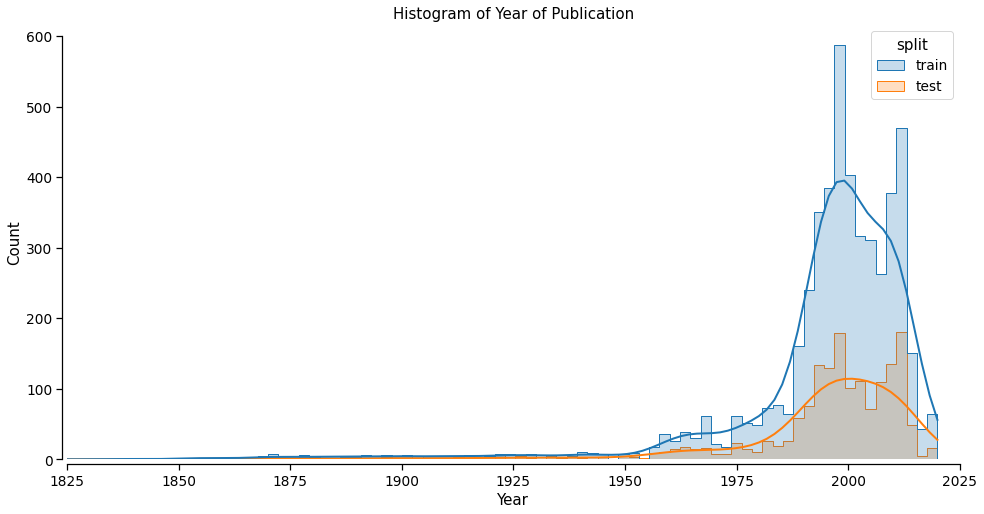
Using the metadata from the catalog records, we compiled a dataset that contains the textual data of books and periodicals from 1674 to 2020, although most of the records are from 1925 to 2020 (see Figures 1 and 2). The 6,600 records are split in two sets, one for training and another for testing, containing 4,950 (75%) and 1,650 (25%) records, respectively. The dataset is balanced in terms of how many records are assigned the positive and negative classes, although we expect there is some noise in this labeling. The total number of words in the dataset is over 250 million (257,732,593).
Model training
With a dataset ready, we had to select one approach to build a classifier. In recent times, artificial neural networks trained using deep learning techniques achieve the best results in tasks related to the processing of natural language. Last year, our lab at the NLN released the first such neural network trained exclusively for the Norwegian language, exhibiting a performance that is still unrivaled to this day (February 2022). NB-BERT, as this model was named, surpassed other multilingual models in the classification of sentiments or the identification of named entities in text. Thus, we decided to put NB-BERT to test on the Sami Bibliography dataset aforementioned. Unfortunately, this new breed of statistical artifacts for language are usually limited to a handful of words, which is very inconvenient when dealing with entire books. Specifically, the BERT-base architecture upon which NB-BERT is built, is only able to work with around 500 words at a time. This means that in order to leverage the prowess of NB-BERT for the classification of records in the Sami Bibliography, we had to split each text into chunks. However, several factors in this chunking might impact the performance of the final classifier. We experimented with several of these parameters: number of words in the chunks, the amount of overlap between any consecutive pair of chunks (defined using a sliding window with an arbitrary width), as well as other internal bits and bolts that need to be adjusted (dropout, learning rate, weight decay, etc.).
Evaluation
In order to assess which of the combinations of options performed better, we measured the four rates of any binary classification problem, i.e., true and false positive rates, and true and false negative rates. As the models trained, we made predictions on the test set to calculate how many times the model was correctly predicting whether a record should or should not belong to the Sami Bibliography, and how many times the model was mislabeling records as relevant or not. With these rates we computed a couple of summary metrics that allowed us to compare the different models trained. Specifically, we used the harmonic mean over precision and recall (F1) and the Matthew’s correlation coefficient (MCC), a couple of metrics that go from zero for really bad performance to one for the best. The evaluation was also done at both the chunk level and the whole record level, depending on the kind of training.
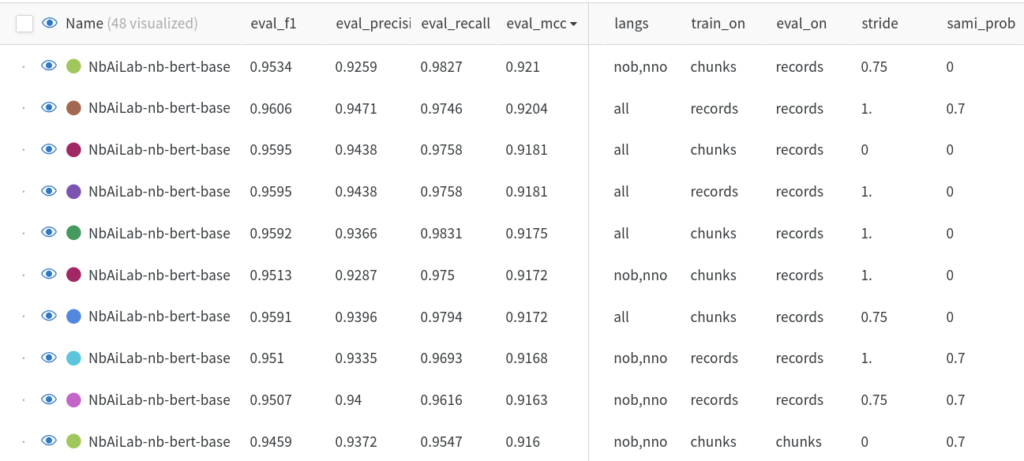
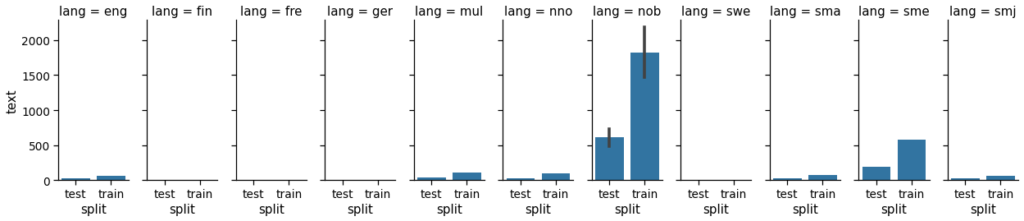
We also evaluated a novel technique that leverages an adjusted version of NB-BERT that learnt to identify passages of text that logically entail each other. This natural language inference (NLI) approach allowed us to assign a score to every chunk of text based on a list of labels created ad-hoc for the task. We then used different threshold values over this score to filter out parts of the training data with the goal of improving the finetuning process of the binary classifier. Figure 3 shows a summary of the 10 best performing models after our experiments. While two of the NLI-based methods performed slightly better than the rest as reported by their F1 score, the MCC score was higher for the models trained normally. Since MCC is in general a more reliable metric for binary classification and since the NLI approach was a two-step pipeline involving doing inference twice plus a prior non-negligible training, we decided to choose the first model based solely on MCC. Our best model was trained on chunks of approximately 500 words of Bokmål and Nynorsk text with a sliding window of 25%. It is important to note that there was no difference between including or excluding the few Sami texts in the dataset (see Figure 4).
Is this book relevant?
From the library catalog, we made a new non overlapping subset of over 55,000 records containing textual information from 1980 to 1989. With our well-performing classifier model in place, we generated the predictions for all the corresponding ~7.8 million chunks and established which ones could potentially be of relevance to the Sami Bibliography. It took a week on a very powerful device to do the inference on the 7,791,233 chunks! A whole record was considered to be of relevance if the majority of its chunks were also considered to be of relevance with a probability over 50%.
Putting it all together
With a model to do predictions, and with the predictions of a decade’s worth of library records, we put the system up for the ultimate test: the Sami bibliographers. Built on top of the predictions of the models, we designed a web-based application around two main components:
- A new and specialized database holding information about the digital documents, including some brief metadata and the result of inference done by our best performing model. Apart from the individual prediction probability scores, an average score was also calculated per document.
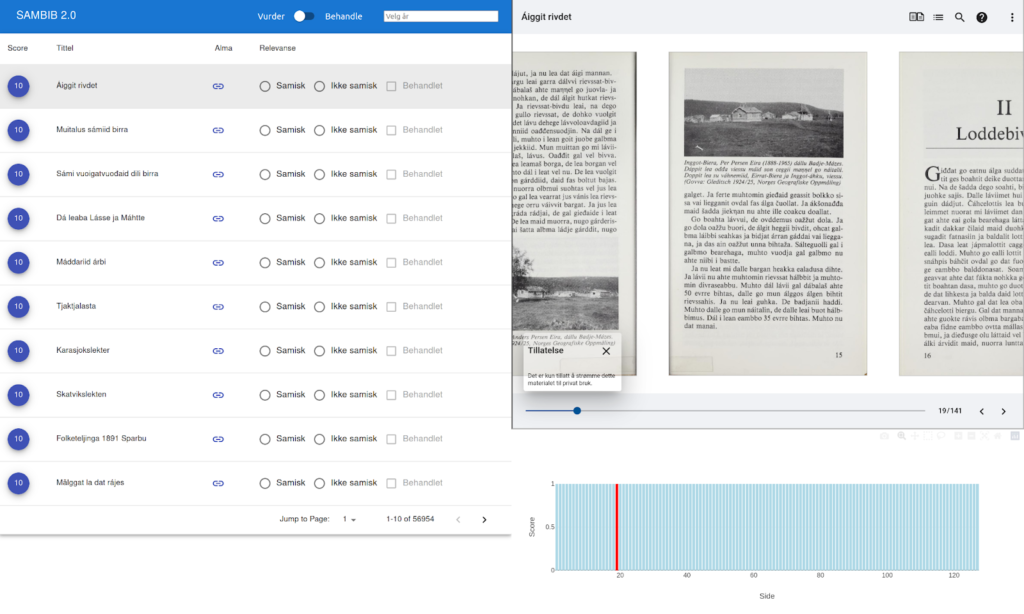
- A web-based user service based on the database and providing support for the workflow in the office. The interface shows a list of all documents for which inference is already performed, and it is sorted by the average probability. There are a few widgets that allow the user to browse through this immense list, flag records for review, select by date, view the IIIF presentation of items, or tag records as resolved (see Figure 5).
By calling this “the first version” we assume that there will be developments and changes based on the experience of the experiment.
Status and future
As from February 2022, the experimental solution is in production and used by the office for the Sami Bibliography. After a few months of usage, we will evaluate its performance and assess its usefulness in assisting our librarians in their daily work.
Bibliographers feedback is essential to steer further development of the application. Nonetheless, a few improvements have already been discussed. For example, adding an automated process doing inference on documents asynchronously as they are accessioned, updating the database and displaying the new records in the web interface. Or, for documents not yet processed, a background job capable of analyzing documents on demand. This process would be based on the inference of our best performing model, which we hope to keep improving as the web application gets used.
With the development of this experiment, from its conception to its deployment, from the many conversations with the bibliographers to the incorporation of their feedback, we hope to set an example on how AI-solutions can be used to successfully assist our librarians with their internal library workflows.