Background
The National Library of Norway (NLN) is well known for its immense digitization efforts. Millions of newspapers, books, photographs etc. have been digitized via a streamlined process of manual labor of scanning – both by hand and with the help of automatic machinery.
One particular system that is used, is attaching several consecutive newspapers into large bundles, which can then be scanned as one unit by a machine, instead of having to constantly switch out the newspapers. However, doing this introduces a problem: where does one newspaper stop and another begin? Today this question is answered by people, tagging where the endpoints of each newspaper is. This is quite a laborious task, that should ideally be done automatically.
Goal
The AI-lab decided to run an experiment, investigating the feasibility of a solution by means of machine learning. By using image recognition, it should be possible to pick out all the front pages – which are typically quite distinct – from every bundle, indicating the end of one newspaper and the start of another.
Making a model
Dataset
In a classification task like this, every model needs a good dataset to lay the foundation. We went through several iterations of datasets and model trainings. The final iteration contains over 59 000 newspapers from a varied set of publishers and years. It includes the front page, the back page, and four pages from the middle of each randomly selected newspaper, with the corresponding labels (front, middle, back).
Model
Once we have the dataset, the training is not very difficult. We tried a few models, but ended up using Google’s Vision Transformer model. The accuracy ended up at around 95% in the 1:4:1 ratio training set, which is very good.
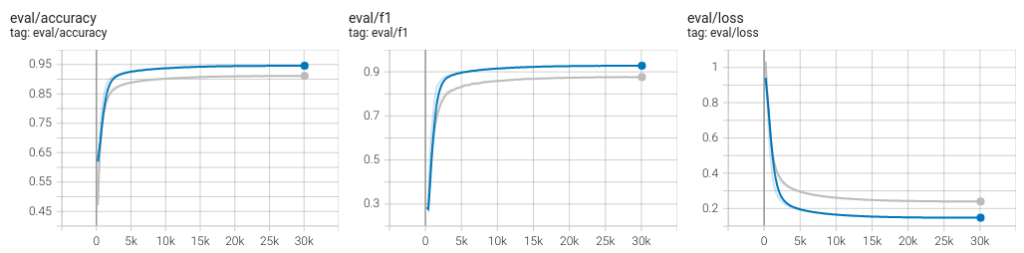
When evaluating on actual full newspapers, the accuracy actually increased slightly. It went up to 96% with all labels, and 99.5% on just separating between front page and not front page. This is extremely good for a machine learning model!
However…
Trouble in paradise
Although the accuracy is incredibly high, the problem is that bundles are often very long. An average bundle contains 383 pages. The task is such that even if a single page is misclassified, the whole bundle will be wrong. A naive estimate of bundle-level accuracy is therefore 0.996³⁸³=22%. This is way too low to replace humans.
Work smarter, not harder
Instead of attempting endless incremental improvements to the dataset and the model, we can take advantage of some extra information we have:
- The model outputs a confidence level in its prediction, in the form of probabilities, for each of the three classes.
- The model also predicts back pages, hinting that the next page is front. Back pages are generally harder to guess correctly, but the signal can still be used.
- First page in bundle is always a front page. Since a bundle is always a single publisher, we can use this to compare every page with the very first page in the bundle.
- Front pages can only occur on page 1, 3, 5, etc. (odd numbers) since newspapers are always an even number of pages. By the same logic, back pages must always be even.
- The most useful information (e.g. logo, date) is often contained in the top of the newspapers. We can train a separate model that only looks at front pages, and use that model for extra robustness in predictions.
- The bundle ID tells us how many newspapers we should expect to find.
The full system
With all of this put together, this is a diagram of the final system.
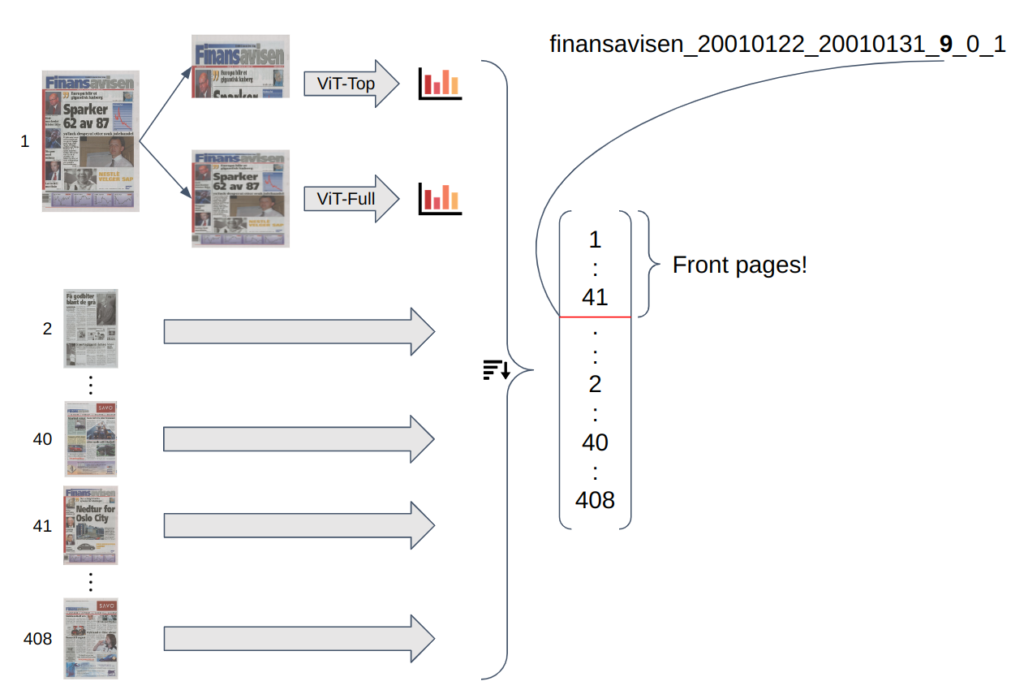
First, every page is run through each of the two models, generating a set of probabilities of the page being front, middle, or back, as well as a vector representing the contents of the page. After all the pages are evaluated, all the info for all the pages is used to create a rank order of pages, with all the front pages (hopefully) ending up at the top. Using the bundle ID we then select the top N most likely pages, and declare those to be front pages.
Using this method, the system is able to correctly predict 65 072 out of all the 66 750 bundles ever processed at the National Library correctly. That’s a bundle-level accuracy of 97.5%!
Taking it into use
Through collaboration with Team Text at the National Library, we are working on bringing this system out of experiments and into a working production system. This would be the first example of an AI system being used in a production line at the Library.